The web is everywhere!
We use it more than we ever did before - also in many places where you might not see it. Because "the web" is more than just websites you visit by entering a URL in your browser.
No matter if you check your e-mails on your mobile phone or if you're sending a tweet - you are using the internet (i.e. "the web").
How does all that work? Which technologies are involved and what do you need to learn (and to what extent) if you want to become a web developer?
In this article and video (see above), I will not dive into all technical details. This is meant to be a good overview of the web functionality.
Related Premium Courses


#How Websites Work
Let's start with the most obvious way of using the internet: You visit a website like academind.com.
The moment you enter this address in your browser and you hit ENTER, a lot of different things happen:
- The URL gets resolved
- A Request is sent to the server of the website
- The response of the server is parsed
- The page is rendered and displayed
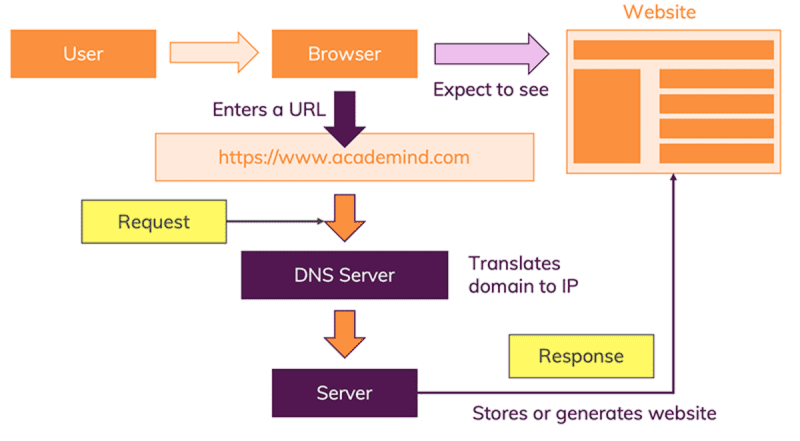
Actually, every single step could be split up in multiple other steps, but for a good overview of how it all works, that's something we can ignore here. Let's have a look at all four steps.
#Step 1 - URL Gets Resolved
The website code is obviously not stored on your machine and hence needs to be fetched from another computer where it is stored. This "other computer" is called a "server". Because it serves some purpose, in our case, it serves the website.
You enter "academind.com" (that is called "a domain") but actually, the server which hosts the source code of a website, is identified via IP (= Internet Protocol) addresses. The browser sends a "request" (see step 2) to the server with the IP address you entered (indirectly - you of course entered "academind.com").
In reality, you also often enter "academind.com/learn" or anything like that. "academind.com" is the domain, "/learn" is the so-called path. Together, they make up the "URL" ("Uniform Resource Locator").
In addition, you can visit most websites via "www.academind.com" or just "academind.com". Technically, "www" is a subdomain but most websites simply redirect traffic to "www" to the main page.
An IP address typically looks like this: 172.56.180.5 (though there also is a more "modern" form called IPv6 - but let's ignore that for now). You can learn more about IP addresses on Wikipedia.
How is the domain "academind.com" translated to its IP address?
There's a special type of server out there in the internet - not just one but many servers of that type. A so called "name server" or "DNS server" (where DNS = "Domain Name System").
The job of these DNS servers is to translate domains to IP addresses. You can imagine those servers as huge dictionaries that store translation tables: Domain => IP address.
When you enter "academind.com", the browser therefore first fetches the IP address from such a DNS server.

In case you're wondering: The browser knows the addresses of these domain servers by heart, they're programmed into the browser so to say.
Once the IP address is known, we advanced to step 2.
#Step 2 - Request Is Sent
With the IP address resolved, the browser goes ahead and makes a request to the server with that IP address.
"A request" is not just a term. It really is a technical thing that happens behind the scenes.
The browser bundles up a bunch of information (What's the exact URL? Which kind of request should be made? Should metadata be attached) and sends that data package to the IP address.
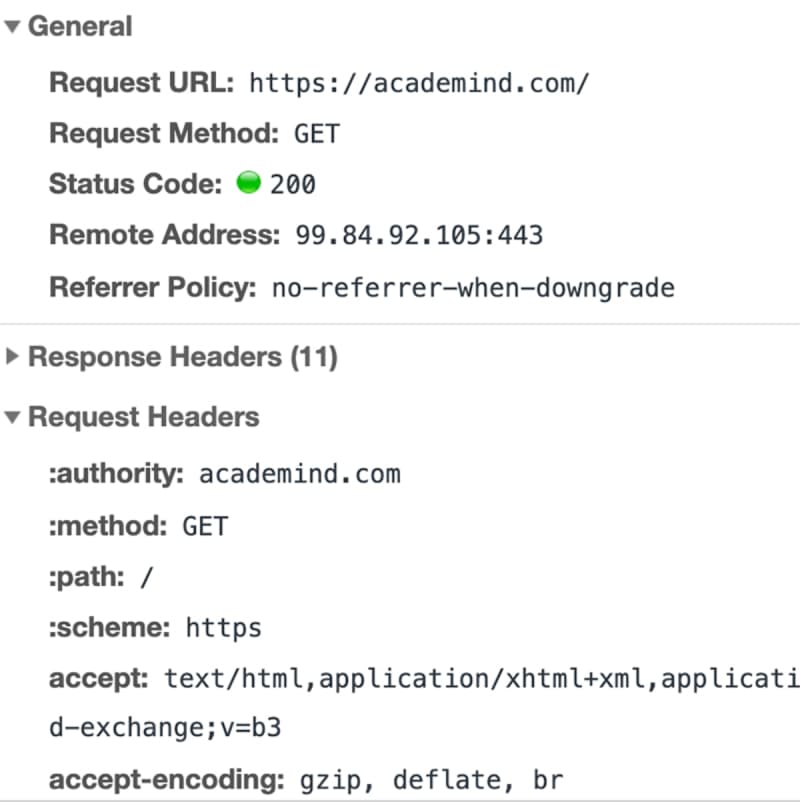
The data is sent via the "HyperText Transfer Protocol" (known as "HTTP") - a standardized protocol which defines what a request (and response) has to look like, which data may be included (and in which form) and how the request will be submitted. You can learn more about HTTP here.
Because HTTP is used, a full URL actually looks like this: http://academind.com. The browser auto-completes it for you.
And there also is HTTPS - it's like HTTP but encrypted. Most modern pages (including academind.com) use that instead of HTTP. A full URL then becomes: https://academind.com.
Since the whole process and format is standardized, there is no guessing about how that request has to be read by the server.
The server then handles the request appropriately and returns a so called "response". Again, a "response" is a technical thing and kind of similar to a "request". You could say it's basically a "request" in the opposite direction.
Like a request, a response can contain data, metadata etc. When requesting a page like academind.com, the response will contain the code that is required to render the page onto the screen.

What happens on the server?
That's defined by web developers. In the end, a response has to be sent. That response doesn't have to contain "a website". It can contain any data - including files or images.
Some servers are programmed to generate websites dynamically based on the request (e.g. a profile page that contains your personal data), other servers return pre-generated HTML pages (e.g. a news page). Or both is done - for different parts of a webpage. There also is a third alternative: Websites that are pre-generated but that change their appearance and data in the browser.
The different kinds of websites are not really the focus of this article. If you want to learn more about that, check out this article + video.
For our simple case we have a server that returns the code to display a website. So let's continue with step 3.
#Step 3 - Response Is Parsed
The browser receives the response sent by the server. This alone, doesn't display anything on the screen though.
Instead, the next step is that the browser parses the response. Just as the server did it with the request. Again, the standardization enforced by HTTP helps of course.
The browser checks the data and metadata that's enclosed in the response. And based on that, it decides what to do.
You might've had cases where a PDF opened in your browser. That happened because the response informed the browser that the data is not a website but a PDF document instead. And the browser tries to pick the best handling mechanism for any data type it detects.
Back to our website scenario.
In that case, the response would contain a specific piece of metadata, that tells the browser that the response data is of type text/html.
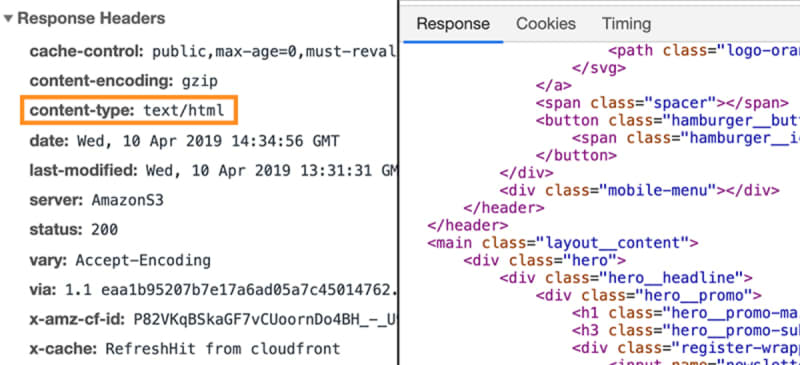
This allows the browser to then parse the actual data that's attached to the response as HTML code.
HTML is the core "programming language" (technically, it's not a programming language - you can't write any logic with it) of the web. HTML stands for "Hyper Text Markup Language" and it describes the structure of a webpage.
The code looks like this:
<h1>Breaking News!</h1> <p>Websites work because browser understand HTML!</p>
<h1> and <p> are so called "HTML tags" and if you want to learn more about HTML, this series is a great place to go.
Every HTML tag has some semantic meaning which the browser understands, because HTML is also standardized. Hence there is no guessing about what a <h1> tag means.
The browser knows how to parse HTML and now simply goes through the entire response data (also called "the response body") to render the website.
#Step 4 - Page Is Displayed
As mentioned, the browser goes through the HTML data returned by the server and builds a website based on that.
Though it is important to know, that HTML does not include any instructions regarding what the site should look like (i.e. how it should be styled). It really only defines the structure and tells the browser which content is a heading, which content is an image, which content is a paragraph etc. This is especially important for accessibility - screen readers get all the useful information out of the HTML structure.
A page that only includes HTML would look like this though:

Not that beautiful, right?
That's why there's another important technology (another "programming language", which isn't really a programming language): CSS ("Cascading Style Sheets").
CSS is all about adding styling to the website. That is done via "CSS rules":
h1 { color: blue; }
This rule would color all <h1> tags blue.
Rules like that can be added inside of the HTML code but typically, they're part of separate .css files which are requested separately.
Without diving into too many details here, that holds one important implication: A website can be made up of more than the data of the first response we get.
In practice, websites fetch a lot of additional data (via additional requests and responses) which are kicked off once the first response arrived.
How does that work?
Well, the HTML code of the first response simply contains instructions to fetch more data via new requests - and the browser understands these instructions:
<link rel="stylesheet" href="/page-styles.css" />
Again, I won't dive into more details here. If you want to learn more about CSS, our Complete Guide will be very useful!
Together with CSS, the browser is able to display webpages like this:

There actually is another programming language involved (this time, it really is a programming language!): JavaScript.
It's not always visible but all dynamic content you find on a website (e.g. tabs, overlays etc.) is actually only possible because of JavaScript. It allows web developers to define code that runs in the browser (not on the server), hence JavaScript can be used to change the website whilst the user is viewing it.
As before, if you want to learn more, check out our JavaScript resources, for example our complete course.
These are the four steps that are always involved when you enter a page address like academind.com and you thereafter see the website content in your browser.
#Server-side vs Browser-side
From the four steps above, you learned that we can differentiate two core "sides" when talking about the web: Server-side and Browser-side (or: Client-side since we can also access the internet without a browser - see below!).
If you're interested in becoming a web developer, it's important to know that you use different technologies and programming languages for these sides.
#Server-side
You need server-side programming languages - i.e. languages that don't work in the browser but that can run on a normal computer (a server is in the end just a normal computer).
Examples would be:
Important: With the exception of PHP, you can also use these programming languages for other purposes than web development.
Whilst Node.js is indeed primarily used for server-side programming (though it's technically not limited to that), Python is also very popular for data science and machine learning.
#Browser-side
In the browser, there are exactly three languages/ technologies you need to learn. But whilst the server-side languages were alternatives, these three browser-side languages are all mandatory to know and understand:
- HTML (for the structure)
- CSS (for the styling)
- JavaScript (for dynamic content)
#"Behind the Scenes" Internet
Thus far, we discussed websites. I.e. the case where you enter a URL (e.g. "academind.com/learn") into the browser and you get a website in return.
But the internet is more than that. Indeed, you use it for more than just that every day!
The core idea of requests and responses is always the same. But not every response is necessarily a website. And not every request wants a website.
The metadata which is attached to requests and responses controls which data is wanted and returned. Of course both parties that are involved (i.e. client and server) need to support the requestes and sent data.
You can't request a PDF from "academind.com" for example. You could send such a request but you wouldn't get back a PDF - simply because we don't support this kind of requested data for this specific URL.
But there are many servers that specialize in providing URLs that return certain pieces of data. Such services are also referred to as "APIs" ("Application Programming Interface").
For example, mobile apps send "invisible" HTTP requests to such APIs (to specific URLs which are known to them) to get or store data. Twitter is fetching the tweet feed for example.
And even on webpages, such "invisible" requests are sent. If you sign up for our newsletter (which you of course should!), no new page will be loaded. Because data is exchanged behind the scenes. Even though the client is the browser in this case, the request which is sent wants no website in return. And the server URL that receives it offers no website - instead, the server knows how to handle your email address.
We could go into way more detail here but this is already a long article. You should now have a good understanding of how the web works and which core technologies are involved.
If you do want to dive deeper, explore the many resources we have on our page, sign up to our newsletter and of course subscribe to our YouTube channel for more in-depth tutorials and content! :)
Definitely also check out the video you find at the top of the page!. Whilst it includes generally the same content, you'll find some extra information there.