21 KiB
KN06 Inhaltsverzeichnis
[TOC]
Challenges
A) Theorie: Scaling up vs. out (vertical vs. horizontal) / Auto Scaling, Load Balancer und High Availability
Ausgangslage:
🔖 Wissen, dass sie für die bevorstehenden Challenges gut nutzen können.
- Theorie-script (noch verlinken)
- Leistungsnachweise (noch verlinken)
B) Lab: Zwei Webserver erstellen und Last mittels Load Balancer gleichmässig verteilen.
Ausgangslage:
🔖 Für dieses Lab verwenden Sie in der AWS Academy den Kurs AWS Academy Introduction to Cloud: Semester 1. In dieser Laborumgebung ist der Zugriff nur auf die AWS-Services beschränkt, die zum Ausführen des Labs erforderlich sind. Wenn Sie versuchen, auf andere Dienste zuzugreifen oder Aktionen auszuführen, die über die in diesem Lab beschriebenen hinausgehen, können Fehler auftreten.
Anleitung:
Für den ersten Challenge der Kompetenz KN06 wechseln Sie ins elfte Modul Module 11 - Load Balancers and Caching. Hier finden Sie die praktische Übung Lab 11 - Load Balancing. Diese ist Schritt für Schritt geleitet.
⚠️ Hinweis:
Die folgenden Challenges bauen auf diesem ersten Lab auf. Versuchen Sie deshalb die Schritte so zu dokumentieren, dass Sie darauf zurückgreifen können.
Modul 11: Lab 11 - Load Balancers and Caching
Das Lab dauert ca. 30'. Führen Sie alle Schritte konzentriert und der Reihe nach durch. Für den Leistungsnachweis zeigen Sie neben der Doku auch noch gleich live, dass der Loadbalancer funktioniert (Browser mehrmals hintereinander reloaden).
Netzwerkschema:
- Load Balancer mit zwei Instanzen: 🔎 Originalbild (oder unten auf das Bild klicken)
1 Load Balancer verteilt requests auf zwei Instanzen 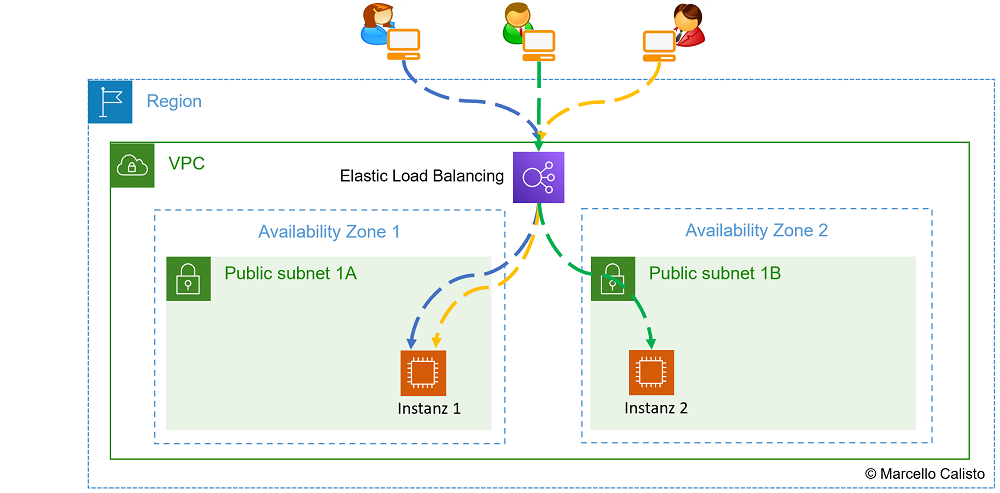
Ziel der Übung
🔔 Sie sind in der Lage, folgende Tasks durchzuführen:
- Application Load Balancer (inkl. Target Group) aufsetzen
- Application Load Balancer testen (mit zwei Webservern in verschiedenen Availability Zones)
Leistungsnachweis
- Ablauf nachvollziehbar im eigenen Repository dokumentiert (für nächste Challenges hilfreich).
- Live-Demo beim Coach (Mit mehrfachem "Reload" der Webseite beweisen, dass beide Instanzen angesprochen werden)
- Fachgespräch mit Coach.
Beachten Sie ausserdem die llgemeinen Informationen zu den Abgaben.
Beispiel-Abgabe (Doku):
- Screenshots :
- LoadBalancer: 🔎 Originalbild (oder unten auf erstes Bild klicken)
- Target Group: 🔎 Originalbild (oder unten auf zweites Bild klicken)
| 2 LoadBalancer | 3 Target Group |
|---|---|
 |
 |
- Webserver 1: 🔎 Originalbild (oder unten auf erstes Bild klicken)
- Webserver 2: 🔎 Originalbild (oder unten auf zweites Bild klicken)
| 4 Webswerver 1 | 5 Webserver 2 |
|---|---|
 |
 |
Wissenswertes vor dem nächsten Challenge:
💡 Für eine perfekte High Availability-Plattform würde dieser Load Balander noch nicht alle Bedingungen erfüllen. Das Beispiel unten zeigt, dass die Instanzen in unterschiedlichen Availability-Zones sind. Damit ist zwar schon mal ein wichtiges Kriterium erfüllt. Was würde jetzt aber passieren, wenn plötzlich gleichzeitig 10'000x mehr Requests reinkämen und die Applikation unter dieser Last zusammenbricht? Genau. Um diesen - oder ähnliche - Use-cases in den Griff zu bekommen, benötigt der Load Balancer Unterstützung von seinem besten Freund, dem Auto Scaler 👬. Was dieser unternimmt und wie er es macht, erfahren Sie gleich, nachdem wir noch abschliessend zu diesem Challenge einen möglichen Use-Case eines Service-Ausfalls (DoS-Attacke) angeschaut haben. Sie werden dann im nächsten Challenge auch gleich selber einen Auto Scaler aufsetzen und diesen dann im übernächsten Challenge mit dem Load Balancer vereinen. 🔧
Use Case: Denial of Service
Denial of Service (DoS) bezeichnet eine Cyberangriffstechnik, bei der ein Angreifer versucht, ein Computersystem oder eine Website durch Überlastung mit Traffic oder Anfragen unzugänglich zu machen. Das Ziel ist, legitimen Nutzern den Zugriff zu verweigern, indem die Ressourcen des Zielsystems erschöpft werden. DoS-Angriffe oder auch gewöhnliche technische Störungen können erhebliche Schäden verursachen und werden durch verschiedene proaktive Sicherheitsmaßnahmen wie Firewalls, Intrusion Detection Systems bekämpft und zusätzlich mit Monitoring-Software überwacht. Der Load Balancer hat aber eine andere Aufgabe und ist nicht darauf ausgelegt, solche Problem zu lösen. Und genau da kommt der Auto Scaler ins Spiel. Der Auto Scaler gehört zu den reaktiven Sicherheitsmassnahmen. Er wird durch einen Trigger aktiviert. Das ist entweder ein Status Check der einen Alarm auslöst, oder eine CloudWatch-Metrics, die eine Grenzwertüberschreitung meldet. Er kommt also erst zum Zug, wenn irgendetwas nicht stimmt. Die vier Bilder unten zeigen genau ein solches Szenario auf.
- Normale Nutzung Load Balancer mit zwei Instanzen: 🔎 Originalbild (oder unten auf erstes Bild klicken)
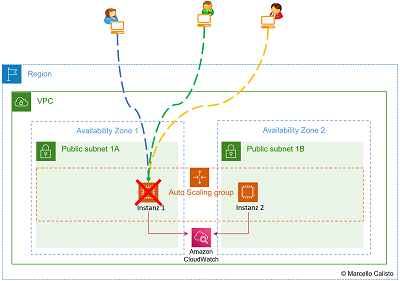
- Denial of Service (Überlastung des Servers): 🔎 Originalbild (oder unten auf zweites Bild klicken)
| 1 Normale Nutzung | 2 Denial of Service (wegen Überlastung) |
|---|---|
 |
 |
- Error Code 500. Der Server ist überlastet.
- User können nicht mehr auf die Applikation zugreifen.
| 4 Rückmeldung des Servers (Error Code 500) | 4 Kein Zugiff auf die Applikation mehr möglich |
|---|---|
 |
 |
C) Lab: Auto Scaling Group erstellen und anwenden
Ausgangslage:
🔖 Für dieses Lab verwenden Sie in der AWS Academy das Learner Lab.
In diesem Challenge werden Sie eine Auto Scaling Group erstellen und später beim Erstellen von neuen EC2-Instanzen nutzen. Der Load Balancer aus dem letzten Challenge und die Auto Scaling Group können unabhängig voneinder eingesetzt werden. Gemeinsam sind diese beiden Dienste allerdings unschlagbar und in einer dynamischen High Availability Umgebung nicht wegzudenken.
Kombiniert man den Auto Scaler mit den Load Balancer, erhält der dahinterliegende Service eine um einiges höhere Verfügbarkeit. Beim Ausfall einer Site (z.B. Datacenter Stromausfall) wird der Traffic automatisch auf die andere Site umgeleitet. Die "verlorenen" Instanzen werden automatisch in der verfügbaren Availability Zone hochgefahren. Zusätzlich kann man den Auto Scaler auch noch mit Metrics ergänzen. Z.B. Falls die CPU-Auslastung einen Grenzwert überschreitet, sollen dynamisch weitere Instanz hochgefahren werden etc... Das ganze funktioniert natürlich auch umgekehrt. Falls die CPU-Auslastung unter den Grenzwert fällt, wird die zusätzliche Instanz automatisch wieder terminiert. Man spricht in diesem Fall von Elasticity. Im Gegensatz zum Begriff Scalability (z.B. Einbau einer weiteren SSD) kann die Plattform on-demand Ressourcen hinzufügen oder entfernen.
Momentan aber schauen wir diese beiden Dienste noch losgelöst voneinander an. Im folgenden Auftrag geht es deshalb nur um die Vorzüge des Auto Scalers. Er stellt sicher, dass meine Ressourcen immer dem gewünschten Zustand (Desired state) entsprechen. Im folgenden Challenge setzen wir diesen Dienst so auf, dass immer mindestens zwei EC2-Instanzen laufen. Falls eine Instanz wegfällt (z.B. versehntlich terminiert, SW-Issue oder technischer Defekt) wird automatisch eine neue Instanz hochgefahren.
Aufgaben des Auto Scalers:
- Launchen und terminieren von EC2-Instanzen dynamisch.
- Horizontal skalieren (Scale out).
- Unterstützt Elasticity und Scalability.
- Reagiert auf EC2 Status Checks und CloudWatch-Metrics.
- Skaliert On-demand (Performance) und/oder gemäss Planung (Falls man z.B. weiss, dass am Sonntagabend ein Backup-Job viel Ressourcen braucht).
Netzwerkschema:
- Auto Scaling Group reagiert dynamisch auf Status Checks und CloudWatch Metrics: 🔎 Originalbild (oder unten auf das Bild klicken)
1 Auto Scaling Group überwacht Status Checks und CloudWatch Metrics 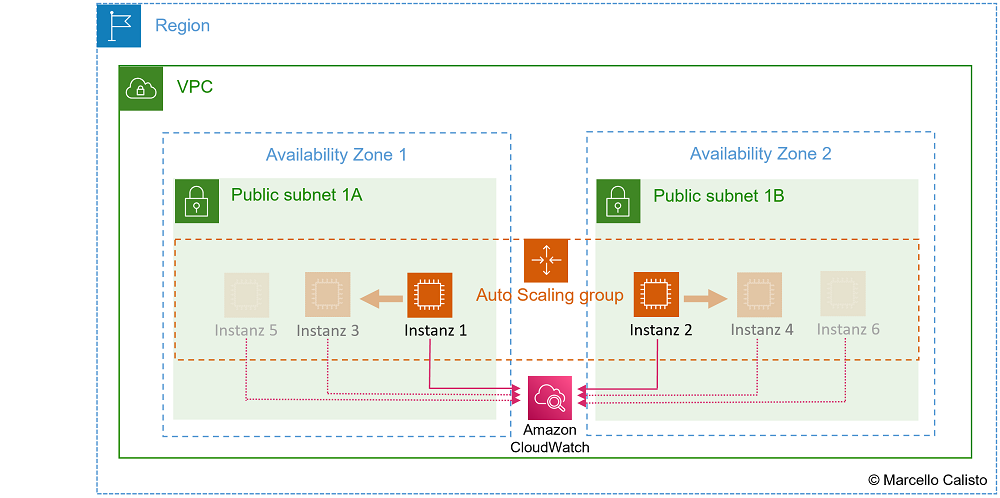

Gleichzeitig erkennt man hier aber sofort auch die Grenzen des Auto Scalers. Er ist zwar in der Lage, aufgrund von status checks und CloudWatch-Metrics den Gesundheitszustand der Instanzen zu checken und entsprechend zu reagieren (z.B. beim Ausfall einer EC2-Instanz eine Ersatz-Instanz hochzufahren), aber er ist alleine nicht in der Lage, die Last gleichmässig zu verteilen und dabei auch die neuen Instanzen einzubinden. Und genau hier kommt ihm sein bester Freund, der Load Balancer, zur Hilfe 👬. Der Auto Scaler sorgt also quasi im Hintergrund dafür, dass immer ausreichend (nicht zuviel, aber auch nicht zuwenig) Ressourcen vorhanden sind, während der Load Balancer vorne praktisch als Türsteher dafür sorgt, dass diese Ressourcen gleichmässig genutzt werden. Weil die Ressourcen nun dynamisch angepasst werden und über zwei oder mehrere Availability Zones verteilt sind, sind sämtliche Anforderungen an eine High Availability-Architektur erfüllt.
Anleitung:
Als erstes werden Sie ein Launch Template erstellen.
Schritt 1: Launch template erstellen
Setzen Sie als erstes ein Launch-Template auf. Wählen Sie dazu links in der Navigation Bar unter Instances den Buttom Create Launch template aus. Dann konfigurieren Sie das LaunchTemplate mit folgenden Parametern:
- Launch template Name: KN06_XXX_LaunchTemplate (XXX = Gemäss Namenskonvention)
- Application and OS Image:
Amazon Linux 2023 AMI (AWS) - Instance type:
t2.micro - Key-pair name:
Don't include in launch template - Network settings:
- Subnet
Don't include in launch template - Security-Groups
M346-XXX-Web-Accessauswählen
- Subnet
- Advanced Details (unter User data):
- diesen Code eingeben (Copy/Paste). Bitte darauf achten, dass nur der Code eingegeben wird. Die Erklärungen helfen Ihnen lediglich, den Code zu verstehen. Später, beim Leistungsnachweis, wird von Ihnen erwartet, dass Sie diesen bis ins Detail erklären können.
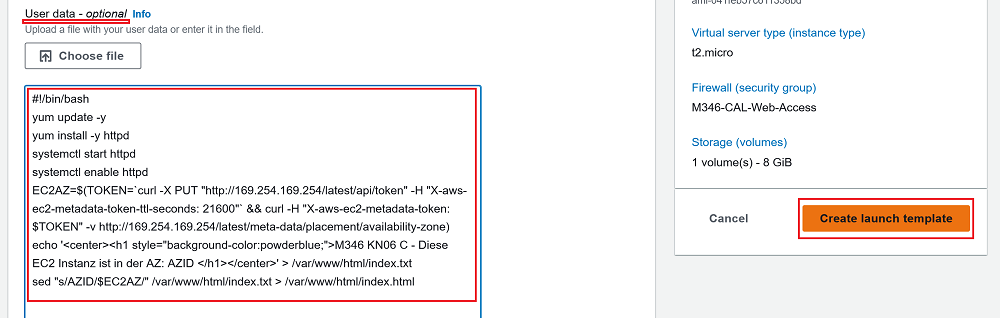 |
|
- diesen Code eingeben (Copy/Paste). Bitte darauf achten, dass nur der Code eingegeben wird. Die Erklärungen helfen Ihnen lediglich, den Code zu verstehen. Später, beim Leistungsnachweis, wird von Ihnen erwartet, dass Sie diesen bis ins Detail erklären können.
- Buttom Create launch template anklicken: (Template wird erstellt)
- Buttom View launch template anklicken: (Kontrolle)
Schritt 2: Auto Scaling Group erstellen
Wählen Sie wieder links in der Navigation Bar unter Auto Scaling das Unterverzeichnis Auto Scaling Groups aus. Dann klicken Sie auf den orangen Buttom Create Auto Scaling group. Danach erscheint eine neue Seite mit dem Titel Choos launch template, welches Sie wie folgt ausfüllen:
- Name:
- Auto Scaling group name:
KN06_XXX_AutoScalingGroup - Launch Template:
KN06_XXX_LaunchTemplate
...sonst nichts ändern und mit Next bestätigen. Es erscheint eine neue Seite mit dem Titel Choose instance launch options, welches Sie wie folgt ausfüllen:
- Auto Scaling group name:
- Launch template (VPC und beide Public Subnets): 🔎 Originalbild (oder unten auf erstes Bild klicken)
- Launch options (No LB und No VPC Lattice Service): 🔎 Originalbild (oder unten auf zweites Bild klicken)
1 Launch template: Korrekte VPC und beide Public Subnets auswählen 2 Launch options: No load balancer 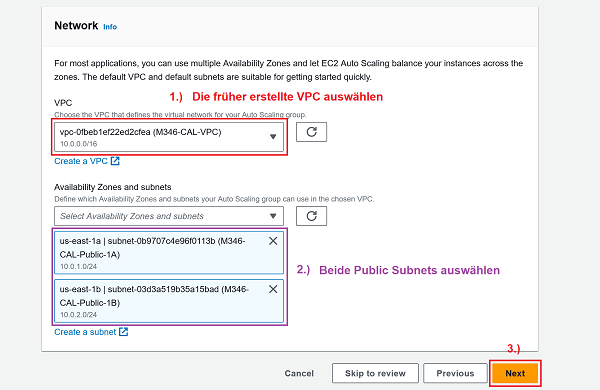
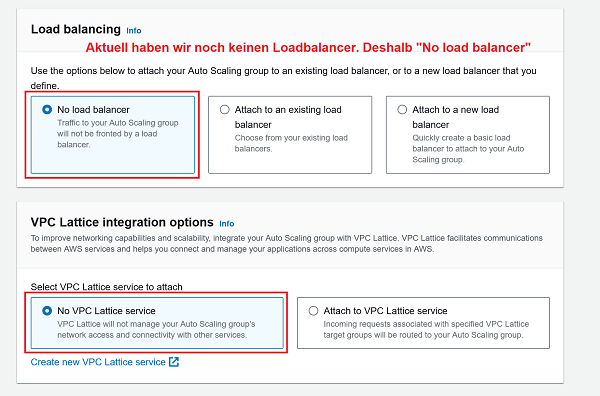
- 1 Nun wird noch die Group size definiert. Wieviele Instanzen im gewünschten-, maximalen und minimalen Zustand laufen sollen.
2 Die Scaling policy (Dynamische Anpassung on demand) wird in diesem Challenge nicht genutzt. Deshalb auf None lassen.Group Size und Scaling policies Entsprechende Werte zuweisen - Desired capacity: Gewünschte Anzahl Instanzen - 2
- Minimum capacity: (Intervention, wenn weniger als 2 Instanzen)
- Maximum capacity (Intervention, wenn mehr als 2 Instanzen)
- Mit der Bestätigung
Create Auto Scaling Groupdie Auto Scaling Group erstellen.


Schritt 3: Check
-
Activity history anschauen: Hier sieht man, dass die Auto Scaling Group bereits aktiv eingegriffen hat. Es wurden zwei EC2-Instanzen gemäss den ganz am Anfang definierten Informationen im Launch template gelauncht (Increasing the capacity from 0 to 2).
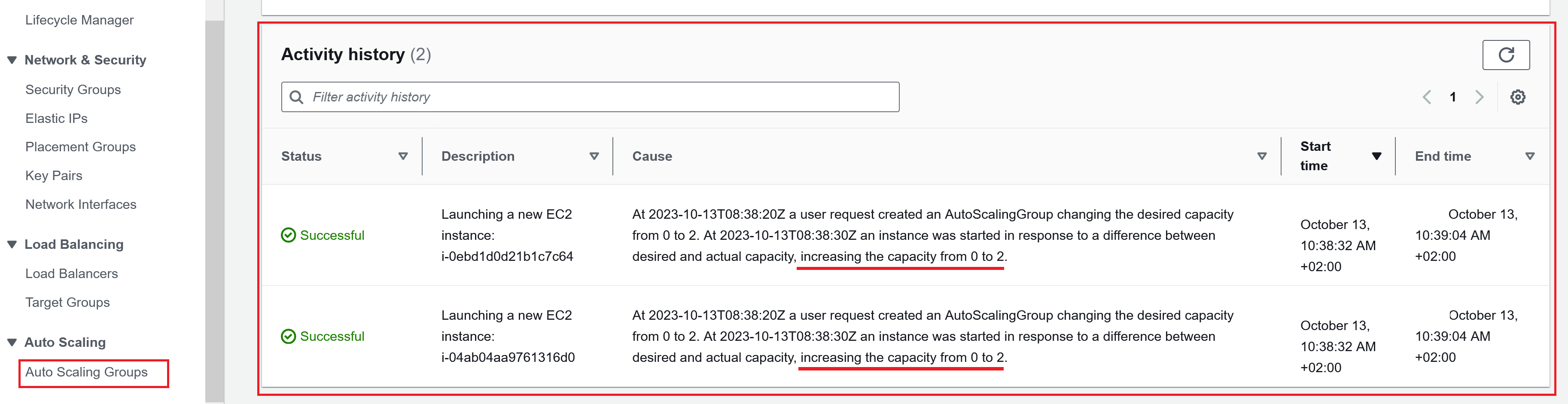
⚠️ Hinweis:
Sinnesgemäss sollten die beiden Instanzen in unterschiedlichen Availability Zones liegen. Überprüfen wir kurz, ob das so ist: -
1.) Erste EC2 Instanz (PublicIP: 18.232.128.55) : 🔎 Originalbild (oder unten auf erstes Bild klicken)
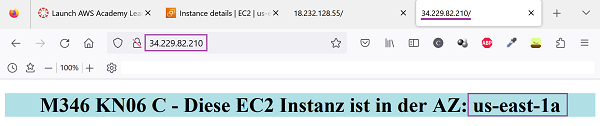
2.) Zweite EC2 Instanz (PublicIP: 34.229.82.210): 🔎 Originalbild (oder unten auf zweites Bild klicken)Erste EC2 Instanz (PublicIP: 18.232.128.55) Zweite EC2 Instanz (PublicIP: 34.229.82.210) 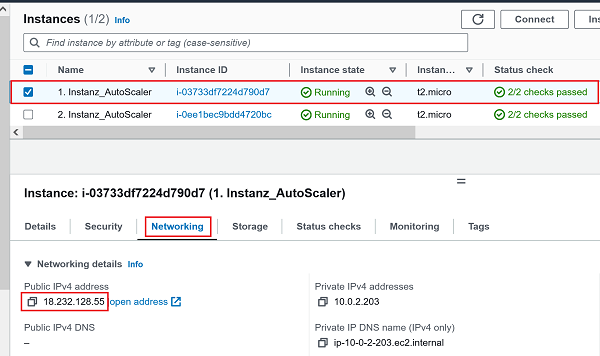
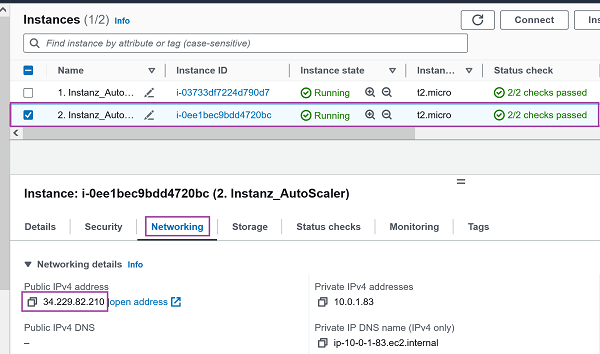
✔️ Beweis:
Beide Instanzen befinden sich in unterschiedlichen Availability Zones: -
1.) Zugriff auf erste EC2 Instanz (PublicIP: 18.232.128.55) - us-east-1b : 🔎 Originalbild (oder unten auf erstes Bild klicken)
2.) Zugriff auf zweite EC2 Instanz (PublicIP: 34.229.82.210) - us-east-1a: 🔎 Originalbild (oder unten auf zweites Bild klicken)Erste EC2 Instanz (AZ: us-east-1b) Zweite EC2 Instanz (AZ: us-east-1a) 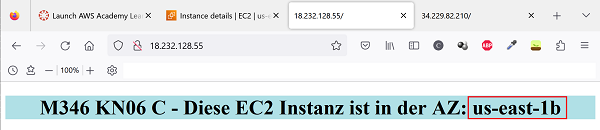
Ziel der Übung




🔔 Verständnisaufbau für Merkmale, die eine High availability-Architektur auszeichnen. Sie wissen, wie eine Auto Scaling Group aufgesetzt wird und was sie genau macht. Sie kennen den Unterschied zwischen Scaling up (Vertikale Skalierung) und Scaling out (Horizontale Skalierung) und verstehen, wie die Services Auto Scaling Group und Load balancer arbeiten und wie sie sich gegenseitig ergänzen.
Leistungsnachweis
- Das Launch template ist korrekt erstellt worden (gemäss Namenskonvention).
- Die Auto Scaling Group ist korrekt erstellt worden (gemäss Namenskonvention).
- Zwei Webserver-Instanzen in unterschiedlichen Availability Zones wurden gemäss Launch template erstellt.
- Differenziert und nachvollziehbar im persönlichen Repository dokumentiert.
- Fachgespräch mit Coach.
- Sie kennen die Details des verwendeten User-data scripts
- Sie kennen den Unterschied zwischen Auto-scaler und Load Balancer.
- Sie verstehen, was High availability bedeutet und können diesen Begriff differenziert anhand eines Beispiels erklären.
Beachten Sie ausserdem die allgemeinen Informationen zu den Abgaben.
D) Lab: Load Balancer / High Availability
Ausgangslage:
🔖 Für dieses Lab verwenden Sie in der AWS Academy das Learner Lab. Es baut auf dem vorangegangenem Challenge B) auf. Das heisst: Die Auto Scaling Group existiert bereits und hat zwei Instanzen in zwei verschiedenen Availability Zones erstellt. Falls Sie in der Zwischenzeit das Lab aus- und wieder eingeschaltet haben sollten, ist das kein Problem. Die Auto Scaling Group ist persistent und startet die Instanzen wieder automatisch, wenn Sie das Lab starten. 📌 Das heisst aber auch, dass Sie diese und alle dazugehörigen Ressourcen am Ende dieses Challenges unbedingt löschen sollten.
Nun. Im ersten Challenge von KN06 haben Sie einen Load Balancer erstellt. Im zweiten Challenge dann haben Sie im Learner Lab eine Auto Scaling Group erstellt. Sie haben auch erfahren, wie diese beiden Dienste funktionieren, dass sie beste Freunde sind und sich perfekt ergänzen. Nun gilt es also, im Learner Lab noch den Load Balancer aufzusetzen und diesen mit dem bereits funktionierenden Auto Scaler zu vereinen. Wenn alles funktioniert, haben Sie am Ende dieses Challenges die beireinste Form einer hochverfügbaren Plattform geschaffen. Dies, weil auch der vermeintlich einzige Single Point of Failure, der ELB (Elastic Load Balancer), AWS-Intern mehrfach über verschiedene IP-Adressen abgesichert wird.
Anleitung:
Dieser letzte KN06 Challenge setzt einen funktionstüchtigen Auto Scaler aus dem letzten Challenge voraus (zwei EC2-Instanzen in unterschiedlichen AZs sollten ebenfall schon laufen).
⚠️ Hinweis:
Die Umgebung läuft im Moment also wie folgt:
- Die Auto Scaling Group ist im Hintergrund aktiv und sorgt dafür, dass immer mindestens zwei Instanzen laufen.
- Es gibt noch keinen Loadbalancer.
Use Case: Auto Scaler funktioniert, aber ohne Loadbalancer
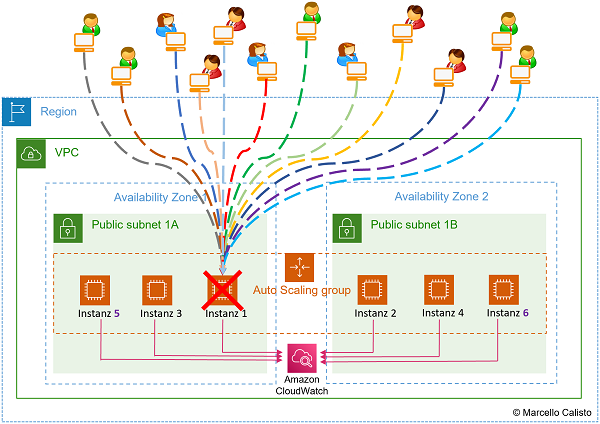
Dieses Beispiel mit einer Reihenfolge von 5 Bildern verdeutlicht, weshalb es nicht viel bringt, wenn man nur den Auto Scaler aufsetzt, ohne ihn mit dem Load Balancer zu ergänzen.
1. Bild:
Wenn nun also User auf die Applikation zugreifen, können sie das theoretisch nur mit der IP-Adresse oder dem DNS.
2. Bild: Das bedeutet, dass die Last nicht gleichmässig verteilt wird. Hier fällt genau die EC2-Instanz aus, auf welche die User zugreifen.
3. Bild: Der Auto Scaler erhält diese Info und ist sofort in der Lage, eine neue Instanz zu starten. Aber so, wie die Umgebung aktuell aufgesetzt ist, können die User nicht ohne weiteres einfach darauf zugreifen.
.... BILDER 4 UND 5 NOCH BESCHREIBEN
Und hier kommt der Loadbalancer ins Spiel. Falls dieser vorhanden wäre, würde er Hand in Hand mit dem Auto-Scaler die aktuellen Infos austauschen und dafür sorgen, dass die Anfragen ausgewogen verteilt werden und .
- Zugriff auf App via IP oder DNS: 🔎 Originalbild (oder unten auf erstes Bild klicken)
- Instanz defekt: 🔎 Originalbild (oder unten auf zweites Bild klicken)
- Auto Scaler reagiert und startet neue Instanz: 🔎 Originalbild (oder unten auf drittes Bild klicken)
1 Zugriff via IP oder DNS 2 Instanz failure 3 Auto Scaler reagiert und startet neue Instanz 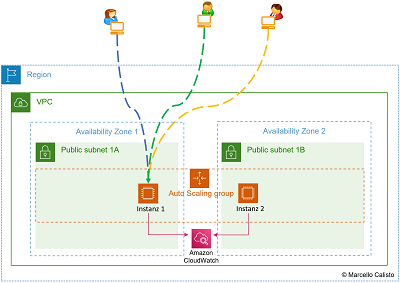
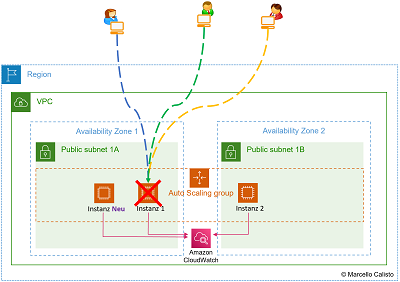
- Mehr Anfragen. Auto Scaler startet mehr Instanzen 🔎 Originalbild (oder unten auf erstes Bild klicken)
- Noch mehr Anfragen. Auto Scaler erstellt noch mehr Instanzen 🔎 Originalbild (oder unten auf zweites Bild klicken)
4 Auto Scaler erstellt mehr Instanzen bei mehr Anfragen 5 Auto Scaler erstellt noch mehr Instanzen bei noch mehr Anfragen 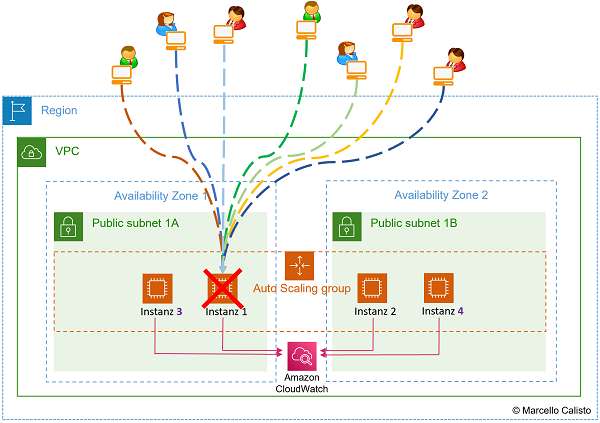





Schritt 1: Launch template erstellen
Setzen Sie als erstes ein Launch-Template auf