12 KiB
KN06 Inhaltsverzeichnis
[TOC]
Challenges
A) Theorie: Scaling up vs. out (vertical vs. horizontal) / Auto Scaling, Load Balancer und High Availability
Ausgangslage:
🔖 Wissen, dass sie für die bevorstehenden Challenges gut nutzen können.
- Theorie-script (noch verlinken)
- Leistungsnachweise (noch verlinken)
B) Lab: Zwei Webserver erstellen und Last mittels Load Balancer gleichmässig verteilen.
Ausgangslage:
🔖 Für dieses Lab verwenden Sie in der AWS Academy den Kurs AWS Academy Introduction to Cloud: Semester 1. In dieser Laborumgebung ist der Zugriff nur auf die AWS-Services beschränkt, die zum Ausführen des Labs erforderlich sind. Wenn Sie versuchen, auf andere Dienste zuzugreifen oder Aktionen auszuführen, die über die in diesem Lab beschriebenen hinausgehen, können Fehler auftreten.
Anleitung:
Für den ersten Challenge der Kompetenz KN06 wechseln Sie ins elfte Modul Module 11 - Load Balancers and Caching. Hier finden Sie die praktische Übung Lab 11 - Load Balancing. Diese ist Schritt für Schritt geleitet.
⚠️ Hinweis:
Die folgenden Challenges bauen auf diesem ersten Lab auf. Versuchen Sie deshalb die Schritte so zu dokumentieren, dass Sie darauf zurückgreifen können.
Modul 11: Lab 11 - Load Balancers and Caching
Das Lab dauert ca. 30'. Führen Sie alle Schritte konzentriert und der Reihe nach durch. Für den Leistungsnachweis zeigen Sie neben der Doku auch noch gleich live, dass der Loadbalancer funktioniert (Browser mehrmals hintereinander reloaden)
Netzwerkschema
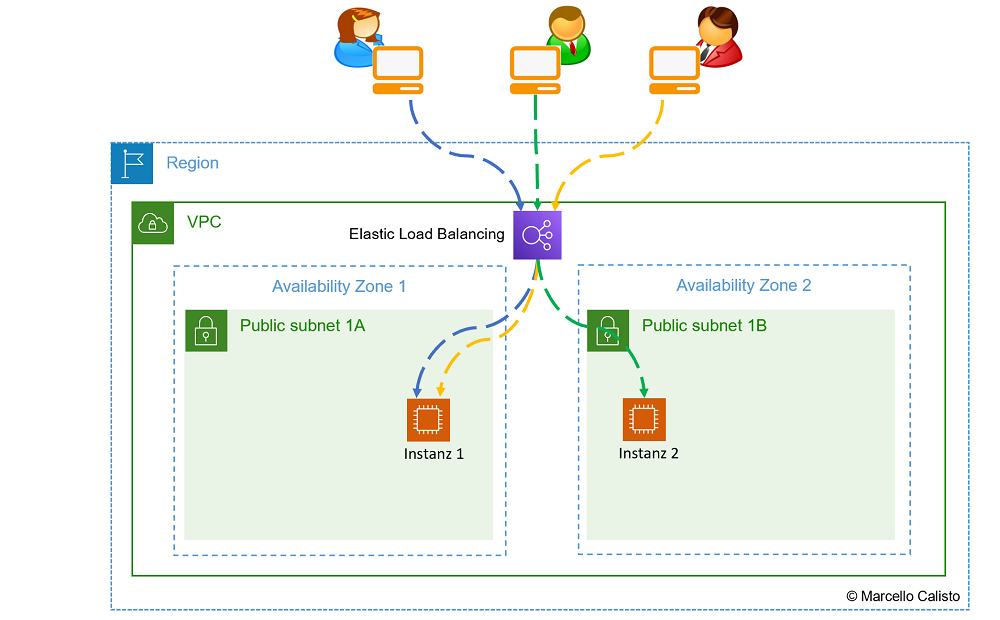 |
|
Netzwerkschema:
- Screenshots :
- LoadBalancer mit 2 Instanzen: 🔎 Originalbild (oder unten auf erstes Bild klicken)
- Loadbalancer mit 4 Instanzen: 🔎 [Originalbild][02b] (oder unten auf zweites Bild klicken)
| 1 LoadBalancer mit 2 Instanzen | 2 LoadBalancer mit 4 Instanzen |
|---|---|
 |
 |
Ziel der Übung
🔔 Sie sind in der Lage, folgende Tasks durchzuführen:
- Application Load Balancer (inkl. Target Group) aufsetzen
- Application Load Balancer testen (mit zwei Webservern in verschiedenen Availability Zones)
Leistungsnachweis
- Ablauf nachvollziehbar im eigenen Repository dokumentiert (für nächste Challenges hilfreich).
- Live-Demo beim Coach (Mit mehrfachem "Reload" der Webseite beweisen, dass beide Instanzen angesprochen werden)
- Fachgespräch mit Coach.
Beachten Sie ausserdem die llgemeinen Informationen zu den Abgaben.
Beispiel-Abgabe (Doku):
- Screenshots :
- LoadBalancer: 🔎 Originalbild (oder unten auf erstes Bild klicken)
- Target Group: 🔎 Originalbild (oder unten auf zweites Bild klicken)
| 1 LoadBalancer | 2 Target Group |
|---|---|
 |
 |
- Webserver 1: 🔎 Originalbild (oder unten auf erstes Bild klicken)
- Webserver 2: 🔎 Originalbild (oder unten auf zweites Bild klicken)
| 3 Webswerver 1 | 4 Webserver 2 |
|---|---|
 |
 |
C) Lab: Auto Scaling Group erstellen und anwenden
Ausgangslage:
🔖 Für dieses Lab verwenden Sie in der AWS Academy das Learner Lab.
In diesem Challenge werden Sie eine Auto Scaling Group erstellen und später beim Erstellen von neuen EC2-Instanzen nutzen. Der Load Balancer aus dem letzten Challenge und die Auto Scaling Group können unabhängig voneinder eingesetzt werden. Gemeinsam sind diese beiden Dienste allerdings unschlagbar und in einer dynamischen High Availability Umgebung nicht wegzudenken.
Kombiniert man den Auto Scaler mit den Load Balancer, erhält der dahinterliegende Service eine um einiges höhere Verfügbarkeit. Beim Ausfall einer Site (z.B. Datacenter Stromausfall) wird der Traffic automatisch auf die andere Site umgeleitet. Die "verlorenen" Instanzen werden automatisch in der verfügbaren Availability Zone hochgefahren. Zusätzlich kann man den Auto Scaler auch noch mit Metrics ergänzen. Z.B. Falls die CPU-Auslastung einen Grenzwert überschreitet, sollen dynamisch weitere Instanz hochgefahren werden etc... Das ganze funktioniert natürlich auch umgekehrt. Falls die CPU-Auslastung unter den Grenzwert fällt, wird die zusätzliche Instanz automatisch wieder terminiert. Man spricht in diesem Fall von Elasticity. Im Gegensatz zum Begriff Scalability (z.B. Einbau einer weiteren SSD) kann die Plattform on-demand Ressourcen hinzufügen oder entfernen.
Momentan aber schauen wir diese beiden Dienste noch losgelöst voneinander an. Im folgenden Auftrag geht es deshalb nur um die Vorzüge des Auto Scalers. Er stellt sicher, dass meine Ressourcen immer dem gewünschten Zustand (Desired state) entsprechen. Im folgenden Challenge setzen wir diese Dienst so auf, dass immer mindestens zwei EC2-Instanzen laufen. Falls eine Instanz wegfällt (z.B. versehntlich terminiert, SW-Issue oder technischer Defekt) wird automatisch eine neue Instanz hochgefahren.
Anleitung:
Als erstes werden Sie ein Launch Template erstellen.
Schritt 1: Launch template erstellen
Setzen Sie als erstes ein Launch-Template auf. Wählen Sie dazu links in der Navigation Bar unter Instances den Buttom Create Launch template aus. Dann konfigurieren Sie das LaunchTemplate mit folgenden Parametern:
- Launch template Name: KN06_XXX_LaunchTemplate (XXX = Gemäss Namenskonvention)
- Application and OS Image:
Amazon Linux 2023 AMI (AWS) - Instance type:
t2.micro - Key-pair name:
Don't include in launch template - Network settings:
- Subnet
Don't include in launch template - Security-Groups
M346-XXX-Web-Accessauswählen
- Subnet
- Advanced Details (unter User data):
- diesen Code eingeben (Copy/Paste). Bitte darauf achten, dass nur der Code eingegeben wird. Die Erklärungen helfen Ihnen lediglich, den Code zu verstehen. Später, beim Leistungsnachweis, wird von Ihnen erwartet, dass Sie diesen bis ins Detail erklären können.
 |
|
- diesen Code eingeben (Copy/Paste). Bitte darauf achten, dass nur der Code eingegeben wird. Die Erklärungen helfen Ihnen lediglich, den Code zu verstehen. Später, beim Leistungsnachweis, wird von Ihnen erwartet, dass Sie diesen bis ins Detail erklären können.
- Buttom Create launch template anklicken: (Template wird erstellt)
- Buttom View launch template anklicken: (Kontrolle)
Schritt 2: Auto Scaling Group erstellen
Wählen Sie wieder links in der Navigation Bar unter Auto Scaling das Unterverzeichnis Auto Scaling Groups aus. Dann klicken Sie auf den orangen Buttom Create Auto Scaling group. Danach erscheint eine neue Seite mit dem Titel Choos launch template, welches Sie wie folgt ausfüllen:
- Name:
- Auto Scaling group name:
KN06_XXX_AutoScalingGroup - Launch Template:
KN06_XXX_LaunchTemplate
...sonst nichts ändern und mit Next bestätigen. Es erscheint eine neue Seite mit dem Titel Choose instance launch options, welches Sie wie folgt ausfüllen:
- Auto Scaling group name:
-
Launch template (VPC und beide Public Subnets): 🔎 Originalbild (oder unten auf erstes Bild klicken)
-
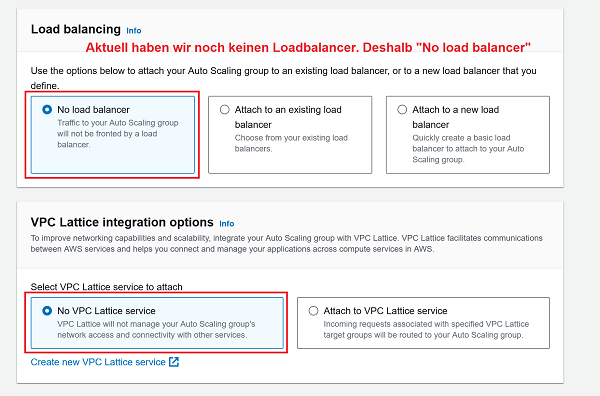
Launch options (No LB und No VPC Lattice Service): 🔎 Originalbild (oder unten auf zweites Bild klicken)
1 Launch template: Korrekte VPC und beide Public Subnets auswählen 2 Launch options: No load balancer 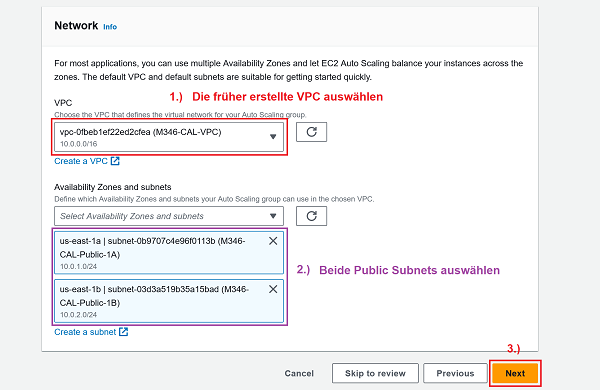
-
1 Nun wird noch die Group size definiert. Wieviele Instanzen im gewünschten-, maximalen und minimalen Zustand laufen sollen.
2 Die Scaling policy (Dynamische Anpassung on demand) wird in diesem Challenge nicht genutzt. Deshalb auf None lassen.Group Size und Scaling policies Entsprechende Werte zuweisen - Desired capacity: Gewünschte Anzahl Instanzen - 2
- Minimum capacity: (Intervention, wenn weniger als 2 Instanzen)
- Maximum capacity (Intervention, wenn mehr als 2 Instanzen)
-
Mit der Bestätigung
Create Auto Scaling Groupdie Auto Scaling Group erstellen.


Schritt 3: Check
-
Activity history anschauen: Hier sieht man, dass die Auto Scaling Group bereits aktiv eingegriffen hat. Es wurden zwei EC2-Instanzen gemäss den ganz am Anfang definierten Informationen im Launch template gelauncht (Increasing the capacity from 0 to 2).
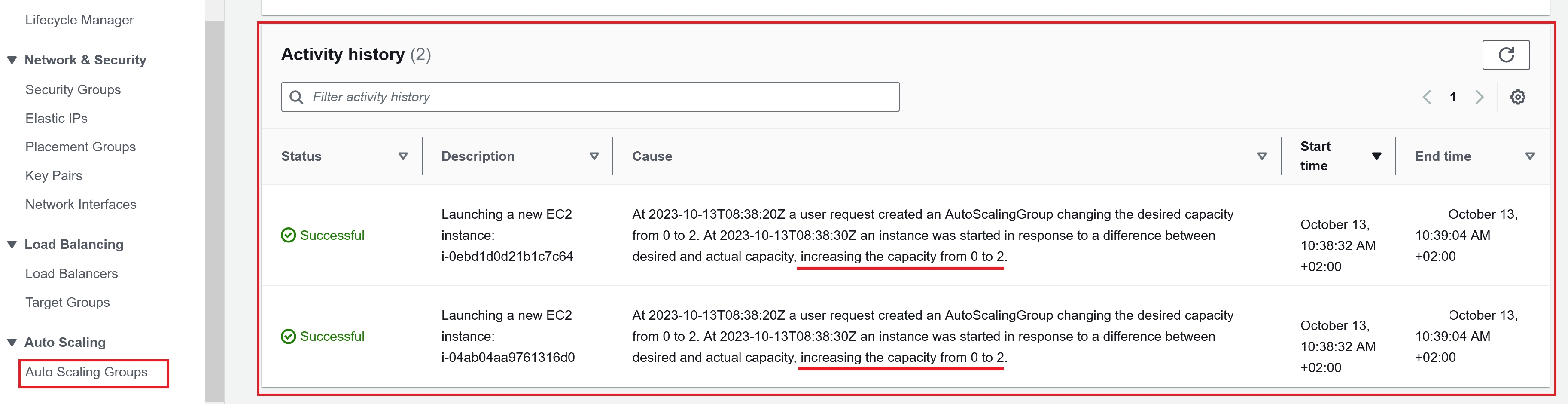
⚠️ Hinweis:
Sinnesgemäss sollten die beiden Instanzen in unterschiedlichen Availability Zones liegen. Überprüfen wir kurz, ob das so ist: -
1.) Erste EC2 Instanz (PublicIP: 3.82.198.9) : 🔎 Originalbild (oder unten auf erstes Bild klicken)
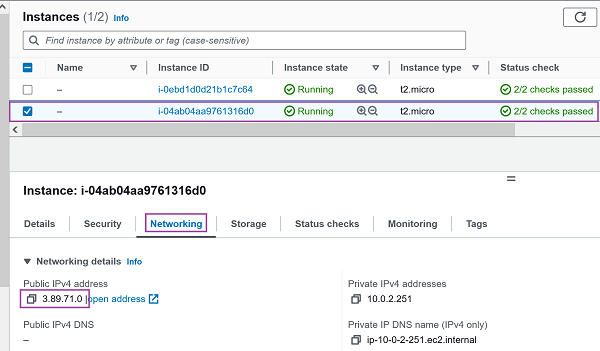
2.) Zweite EC2 Instanz (PublicIP: 3.89.71.0): 🔎 Originalbild (oder unten auf zweites Bild klicken)Erste EC2 Instanz (PublicIP: 3.82.198.9) Zweite EC2 Instanz (PublicIP: 3.89.71.0) 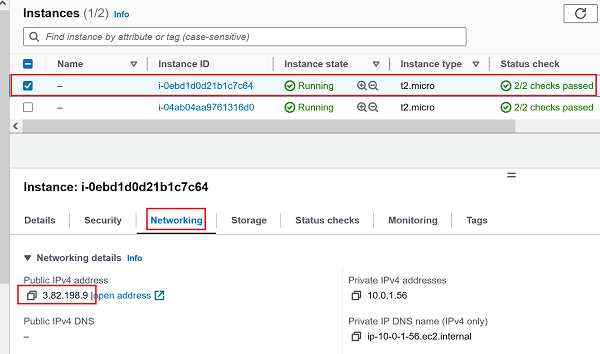
✔️ Beweis:
Beide Instanzen befinden sich in unterschiedlichen Availability Zones: -
1.) Zugriff auf erste EC2 Instanz (PublicIP: 3.82.198.9) - us-east-1a : 🔎 Originalbild (oder unten auf erstes Bild klicken)
2.) Zugriff auf zweite EC2 Instanz (PublicIP: 3.89.71.0) - us-east-1b: 🔎 Originalbild (oder unten auf zweites Bild klicken)Erste EC2 Instanz (AZ: us-east-1a) Zweite EC2 Instanz (AZ: us-east-1b) 

Ziel der Übung




🔔 Verständnisaufbau für Merkmale, die eine High availability-Architektur auszeichnen. Sie wissen, wie eine Auto Scaling Group aufgesetzt wird und was sie genau macht. Sie kennen den Unterschied zwischen Scaling up (Vertikale Skalierung) und Scaling out (Horizontale Skalierung) und verstehen, wie die Services Auto Scaling Group und Load balancer arbeiten und wie sie sich gegenseitig ergänzen.
Leistungsnachweis
- Das Launch template ist korrekt erstellt worden (gemäss Namenskonvention).
- Die Auto Scaling Group ist korrekt erstellt worden (gemäss Namenskonvention).
- Zwei Webserver-Instanzen in unterschiedlichen Availability Zones wurden gemäss Launch template erstellt.
- Differenziert und nachvollziehbar im persönlichen Repository dokumentiert.
- Fachgespräch mit Coach.
- Sie kennen die Details des verwendeten User-data scripts
- Sie kennen den Unterschied zwischen Auto-scaler und Load Balancer.
- Sie verstehen, was High availability bedeutet und können diesen Begriff differenziert anhand eines Beispiels erklären.
Beachten Sie ausserdem die allgemeinen Informationen zu den Abgaben.